Pero por otro lado también he estado aprovechando el tiempo, y el sistema de plugins ya esta bastante maduro. El sistema me ha quedado bastante escueto y portable, por lo que se podría utilizar en otros sistemas que precisen de un sistema de plugins, pero aunque ya haya otros sistemas de plugins para python (y algunos ya se me han adelantado en la idea de convertirlos en sistema "oficial") lo cierto es que no he visto ninguno que tenga algún mecanismo de control de dependencias entre plugins, y aunque creía que iba a ser mas complicado lo cierto es que al final ha sido casi obvio: al cargar el modulo obtenemos las clases de los plugins y vemos cuales son sus dependencias. Si no están todas disponibles dejamos el plugin pendiente, y si lo están entonces lo cargamos y comprobamos entre los pendientes si para alguno de ellos ha cambiado la situación. Simple, fácil y para toda la familia :-D
Es por esto por lo que todavía no le estoy dando mucha popularidad al sistema ya que quiero tenerlo bien fino antes de abrirlo al publico (sobretodo por el tema de los plugins que se meten muy adentro del funcionamiento del sistema), pero probablemente para la versión 0.3 ya haga un llamamiento publico buscando ideas y colaboradores (y si, prometo que intentare poner al día y en la web cuales son los checkpoints para cada versión...). Sin embargo precisamente por esto he estado actualizando (y limpiando) el diagrama de la estructura de tablas mas acorde a como se esta perfilando el sistema ahora que empiezan a funcionar los plugins (mi idea era implementarlo después de la versión 1.0, pero con motivo del concurso y de la "participación de la comunidad" he tenido que cambiar las fechas para hacerlo mas accesible) y este es el resultado:
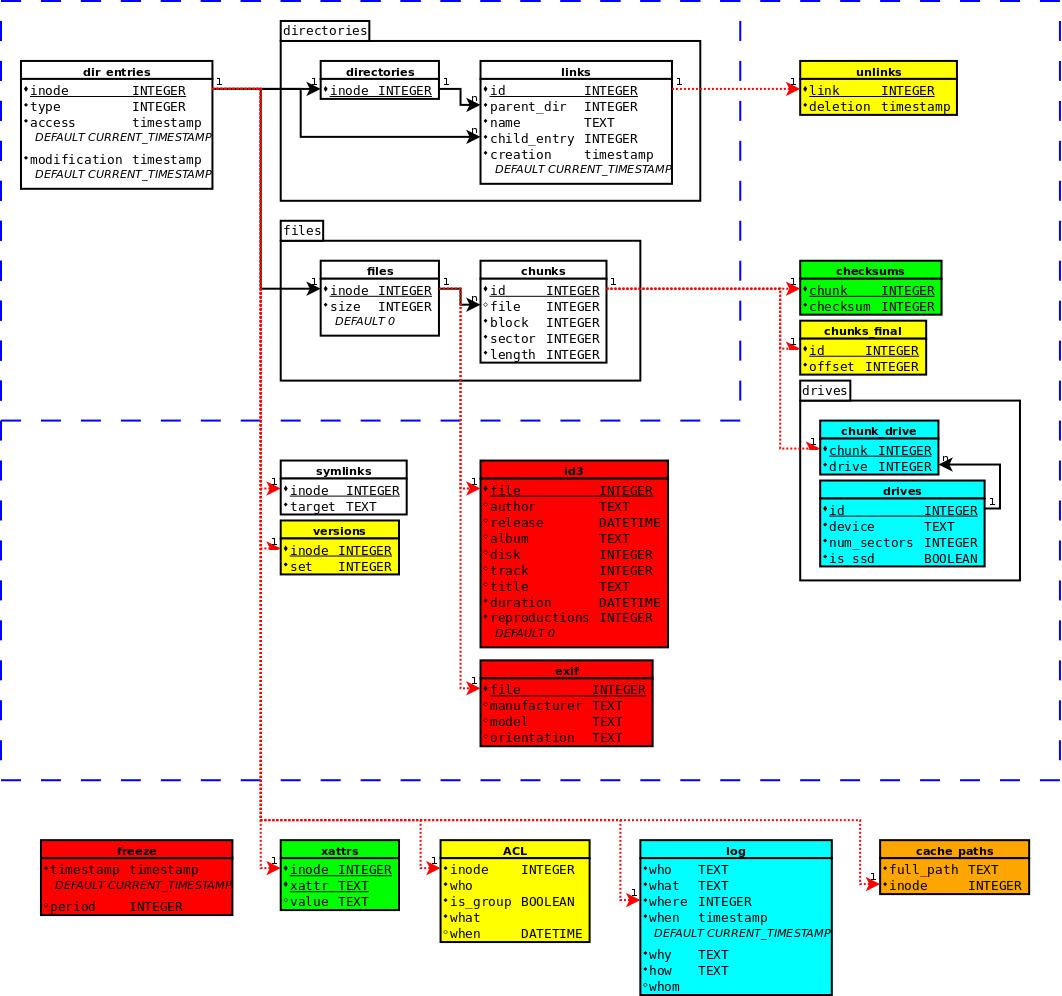 |
| (Los colorines son para indicar la dificultad de implementar cada uno de los modulos según cuanto haya que modificar el código: blanco=implementado, verde=directo o casi directo, amarillo=alguna modificación, naranja=reimplementación en parte, rojo=reimplementación de gran parte y turquesa=implementado pero necesita mejoras. Obviamente, con los checksums me equivoque...) |
Como podéis ver, arriba a la izquierda tenemos el core, ya implementado. He agrupado lo que correspondería al plugin de directorios y al de archivos porque aunque por el momento no tenga pensado implementarlos como modulos externos, lo cierto es que cada vez me esta tentando mas la idea (¡Mama mama, sin directorios! ¡Mama mama, sin archivos! ¡Mama mama, sin datos! X-D). Luego en el siguiente nivel tenemos los modulos de implementación que como dije anteriormente son dependientes de los elementos del core, y por ultimo tenemos los de valor añadido, en los cuales he puesto el ACL y el log (antes los tenia como de implementación) debido a que no son dependientes directos del core. También tengo aquí a un nuevo vecino en el barrio, xattrs (atributos extendidos), que aunque si es dependiente del core lo cierto es que no depende de sus claves únicas. Además, realmente voy a implementar los atributos extendidos para completar la funcionalidad del sistema de archivos y porque va a ser igual de sencillo que los symlinks (al igual que estos, se podría hacer con un mapeo directo de funciones) ya que a titulo personal, me parece una solución mucho mejor el usar algún tipo de estructura como las tablas id3 y exif, no un simple clave-valor que no da ninguna idea de cuales datos faltan por rellenar (lo admito, estoy obsesionado con los tags de los mp3s en el iTunes hasta el punto de que no solo relleno todos los campos de autor/album/disco/pista/titulo para tenerlos bien organizados sino que le meto dentro a los archivos todas las imágenes del album e incluso la letra de las canciones... :-P). Sin embargo también tengo que reconocer que aunque no son muy usados (al menos son unos completos desconocidos para el usuario medio, y para mi hasta hace poco), realmente pueden ser muy potentes y en un sistema de archivos "tradicional" puede ser usado para implementar un ACL y aumentar el nivel de seguridad, por ejemplo. En cualquier caso, para todo lo que se pueden usar los atributos extendidos un sistema dedicado puede cumplir su tarea mucho mejor, pero las estructuras en los sistemas de archivos tradicionales son demasiado fijas como para añadir este tipo de funcionalidades. Por eso la flexibilidad que ofrecen las bases de datos en estos casos es justo una de las razones que me impulsaron a usar una como base para diseñar el sistema de archivos.
Pero este pequeño by-pass con replanteamiento de puntos de vista incluido también me esta permitiendo el tener tiempo para pensar sobre nuevos modulos, plugins y funciones que añadir al sistema, y parte del merito se lo tengo que dar a mi buena amiga Jennifer, una completa n00b para estas cosas (bastante que la conseguí sacar del lado oscuro y que empezara a usar Linux... :-P) pero que sin embargo su punto de vista como usuario raso me ha sido bastante útil (¡gracias! :-D ).
Una de las ideas que me dio fue el implementar algún sistema de búsqueda avanzada en situaciones limite, del estilo "he buscado la foto del garito aquel en la playa en que estuve desfasando con mis amigas en la que salia guapísima, pero no me acuerdo si es de este año o del anterior y no se si las he borrado o que porque no las encuentro" (nota: aunque no haya dicho nada, casi desde que empecé el proyecto en el diagrama arriba a la derecha hay un modulito muy majo llamado "unlinks"... Si, he pensado en todo, también en otro llamado "purge" que no sale ;-) ). "Además, no quiero que salgan las fotos del tío con el que me enrolle esa noche no sea que entre mi novia en un momento inoportuno cuando este buscando la foto" (a esto ultimo lo llamo yo "ganas de fastidiarme", solo que no con estas palabras...). Al leer esto algunos pensaran que eso es imposible, y otros pensaran que quizás SpotLight o Beagle ya lo hacen (realmente esta idea suya les correspondería mas a unas aplicaciones de alto nivel como ellos que a un sistema de archivos, pero un poco de ayuda por debajo les facilitaría mucho la tarea al igual de lo que podría ocurrir si combinásemos ZFS con TimeMachine... :-) ). Lo cierto es que SpotLight es buenísimo (Beagle nunca lo he usado porque siempre lo desinstalaba ya que mis maquinas con Linux nunca han sido lo suficientemente potentes como para encima tener un proceso accediendo al disco todo el rato...) pero nunca he visto que llegara a un nivel de precisión quirúrgica tan avanzado (quizás lanzandolo desde linea de comandos y procesando una consulta muy elaborada, pero si fuera así de fácil habría un montón de artículos escritos en internet al respecto y lo cierto es que no he oído nada). Yo tengo que ser sincero: es muy complicado, pero no imposible. Aquí el mayor problema depende de la adquisición de los metadatos (día-noche, fechas contextualizadas, reconocimiento de caras...) pero si se tienen y están bien organizados, el problema se reduciría a una simple búsqueda en la base de datos. No diré que lo vaya a implementar... pero si que lo tendré en cuenta para orientar posibles mejoras futuras.
Otras ideas que surgieron entre los dos fueron la eliminación segura de archivos (que ya lo tenia pensado antes pero me gusto ver que no soy el único preocupado :-) ) o la compactación de los archivos (quizás para mas adelante, ya hay suficiente lío con la escritura de los chunks como para encima meter esto). Sin embargo al ver todo lo que esta creciendo el sistema me esta entrando una pequeña duda: ¿y si SQLite no es lo suficientemente potente como para moverlo todo? SQLite es un motor de bases de datos muy optimizado, pero tiene el inconveniente de que cuando se accede a el bloque la base de datos entera, y con tanta funcionalidad añadida a falta de pruebas de rendimiento un sistema que ponga a funcionar muchos modulos podría tener problemas... Una solución bastante practica podría ser el que los modulos en lugar de crear sus tablas en la base de datos principal las creen en bases de datos secundarias, con lo que aparte de aumentar la modularización permitirá el acceder en paralelo a las distintas tablas (sobretodo con equipos multicore como los que se venden hoy día) y además se evitaría el meter "mierda" en la base de datos principal y la desinstalación de modulos seria mas sencilla, sin embargo la adaptación a un sistema autocontenido se complicaría sobremanera. Bien es cierto que todavía queda mucho para entonces, pero siempre es bueno planear tus actos con dos o tres pasos de antelación... :-D Por el momento lo dejo aquí anotado como recordatorio para el futuro ;-)
Lo de planteármelo mas seriamente quizás, ya que siempre le he dado mucha mas importancia a la preservación de los datos que a la eliminación.
ResponderEliminarEso si, lo desarrollarlo ni lo dudes (solo es sobreescribir encima de los datos ya existentes), pero eso sera despues de que implemente el plugin de unlinks para recuperar precisamente las cosas borradas por error ;-)